Commons Project Description Universal Representation Learning for Control |
Representation learning can help accelerate learning by summarizing high dimensional data by compressing data into smaller, more manageable vector representations or “features” for learning. Reconstruction-based auto-encoder methods, for example, aim to learn lossless encoding of data, even though most information (e.g. visual shapes of clouds) may be irrelevant for control. Similarity functions also can be provided as domain knowledge in the form of heuristic data augmentation or as known invariances for contrastive learning, but may still be unaware of how those representations will be used by downstream control. In this work we investigate automatic learning of invariances over task-irrelevant information given a set of downstream control tasks.
Researchers |
- Amy Zhang, FAIR, https://amyzhang.github.io/
- Oleksandr Maksymets, FAIR, https://www.linkedin.com/in/maksymets/
- Rowan McAllister, BAIR, https://people.eecs.berkeley.edu/~rmcallister/
- Sergey Levine, BAIR, https://people.eecs.berkeley.edu/~svlevine/
Overview |
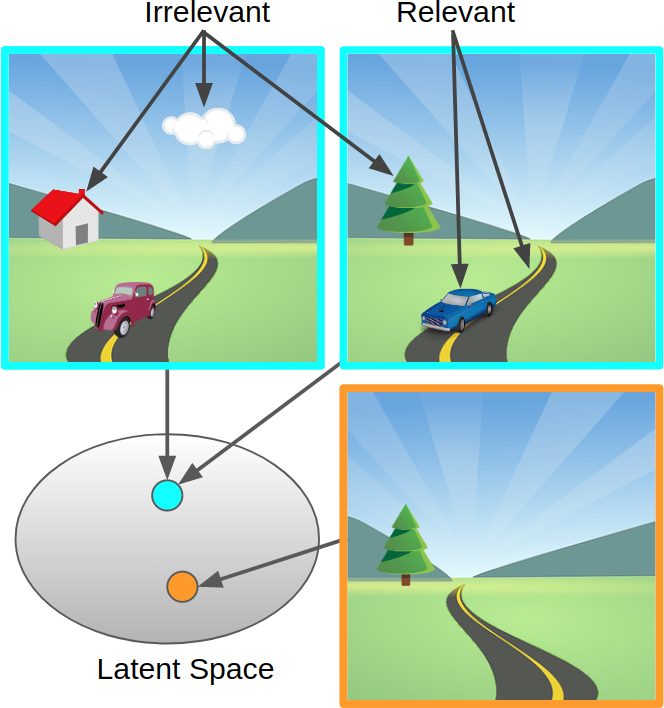
Our prior FAIR-BAIR collaboration investigated deep bisimulation for control (DBC): a method to learn invariances given knowledge of downstream control tasks. This allows for highly compressed representations that automatically learn invariances to task-irrelevant details such as background clouds and shadows, but instead focus on task-relevant information, for example a robot in the foreground (see image below).
Bisimulation embedding Autoencoder embedding
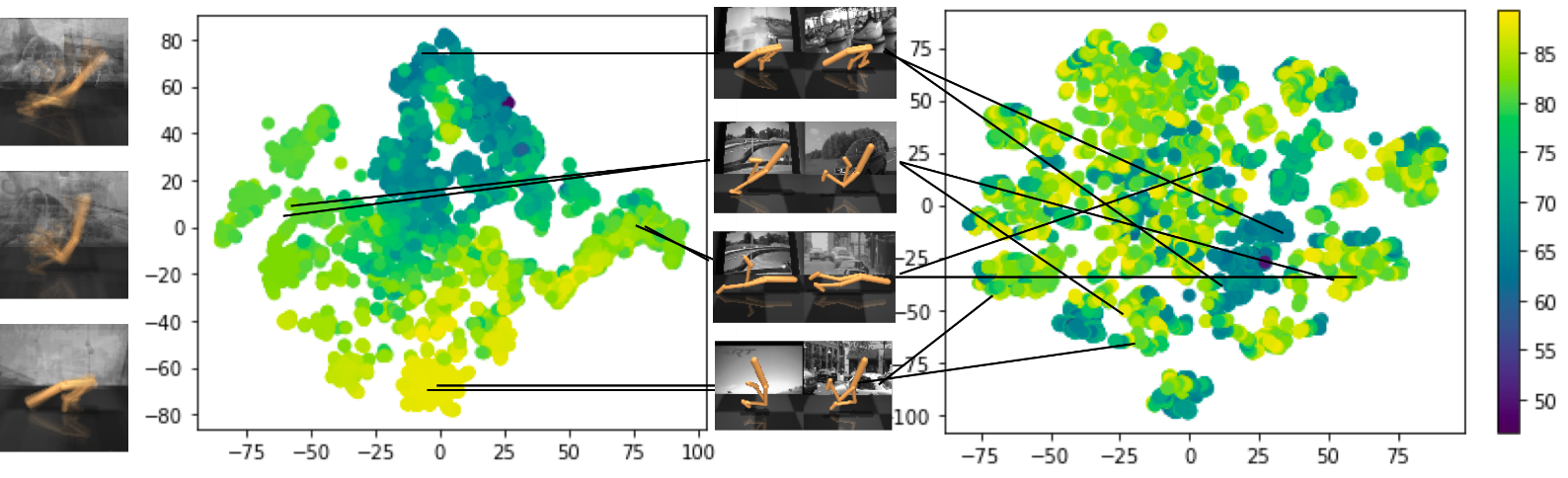
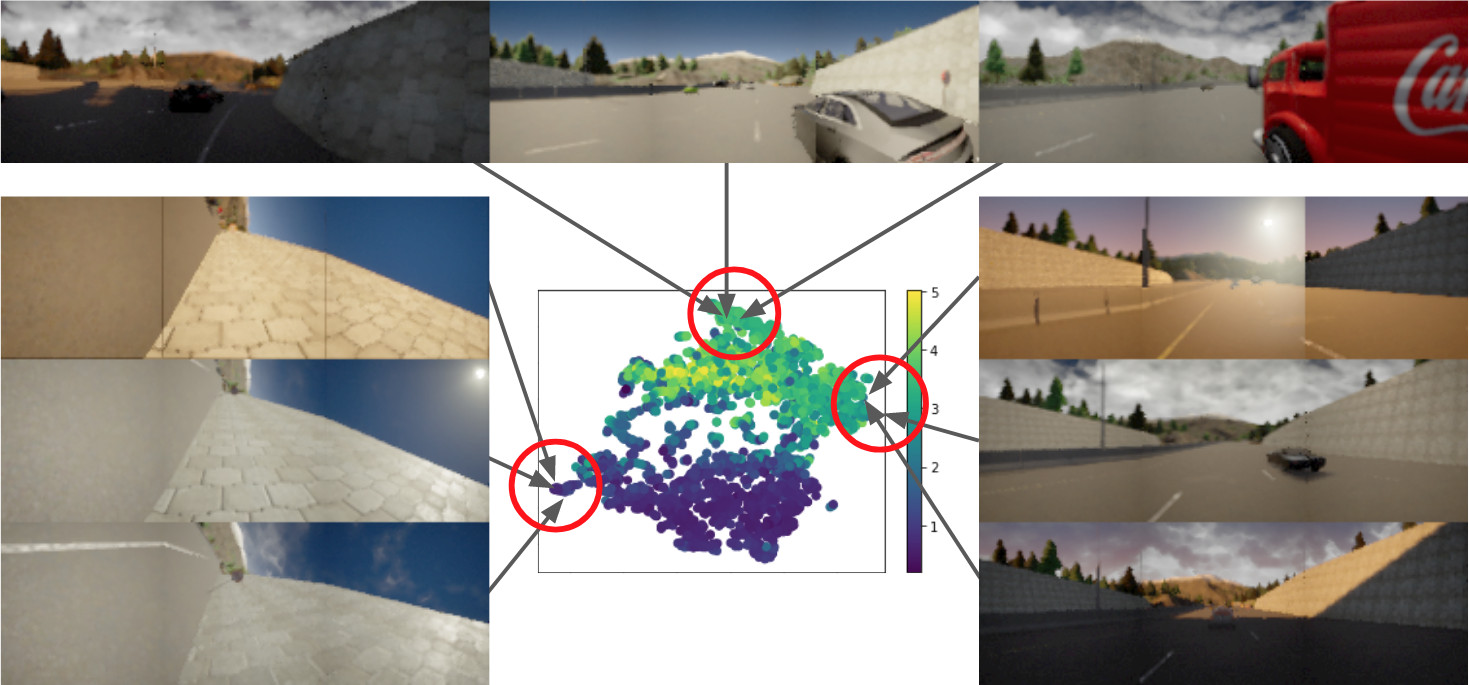
However, this prior work only learned representations on an individual-task basis. Learning universal representations for control would instead give us the ability to learn new tasks rapidly. Real robots are increasingly being used to perform more than just a single task, and universal representations can open the door to learning new tasks rapidly by building off the recent DBC developments. For example, autonomous driving software may be tasked to drive to different destinations, and operate different vehicle types, and adopt different driving styles acceptable to the situation. And yet we could still learn certain invariances w.r.t. Any foreseen task, for example, invance to the weather (see below):
We propose learning universal representations of visual images suitable for downstream control tasks. Such representations would retrain all information relevant to any task, but nothing more. The main benefit and novelty would be the ability to rapidly adapt to new control tasks at test time based on an a-priori learned superset of features. To implement this approach, we would incorporate our recent advances in (single task) deep bisimulation towards conditional bisimulation, a task-conditioned representation learning algorithm that will generalize beyond single tasks to a structured space of tasks. In addition we aim to provide theoretical insights into the type of expected generalization.
Our objective is state-of-the-art data-efficiency in adapting to new navigational and manipulation tasks when presented as natural language queries, such as “bring the bowl to the kitchen”. As long as “bring”, “bowl”, and “kitchen” were individually featured in prior tasks, this proposed algorithm would already understand how to “represent” the three concepts, which would greatly accelerate learning the task of bringing the bowl to the kitchen
Links |