![]()
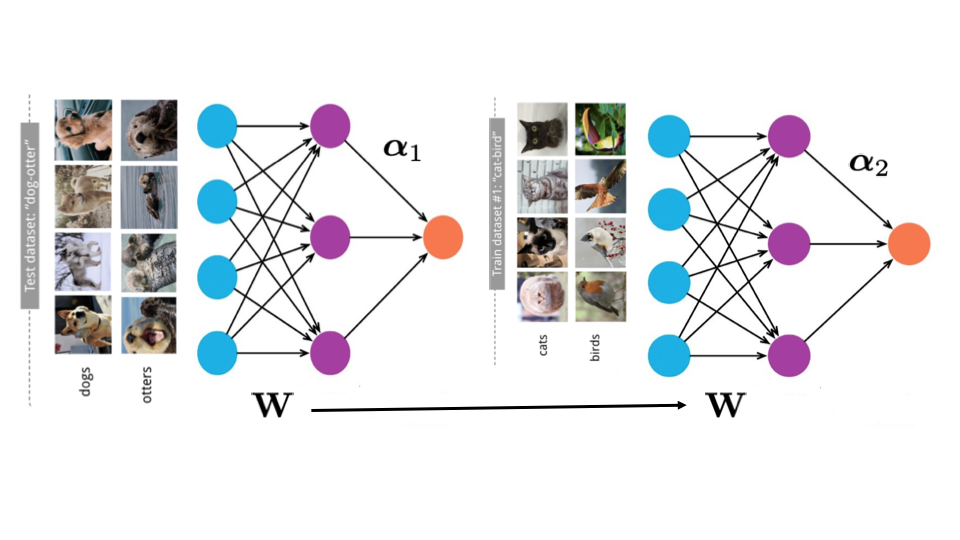
We aim to provide statistical guarantees for transfer learning in sequential settings under dynamic feedback. This can enable coupled learning of several agents across multiple tasks in adaptive settings. Learning shared structure under bandit-style feedback presents additional challenges in comparison to the supervised learning setting, where transfer learning can be achieved by learning a feature representation from independent data. This setting has utility in a broad spectrum of dynamic pricing and RL scenarios.
Update
Researchers
- Nilesh Tripuraneni, U.C. Berkeley, https://people.eecs.berkeley.edu/~nileshtrip/
- Michael I. Jordan, U.C. Berkeley, https://people.eecs.berkeley.edu/~jordan/
- Quentin Berthet, Google Paris, https://q-berthet.github.io/
Overview
In the past, we have provided new statistical guarantees for transfer learning via representation learning--when transfer is achieved by learning a feature representation shared across different tasks. This enables learning on new tasks using far less data than is required to learn them in isolation. In contrast to prior work, our guarantees allow learning guarantees which decay with all available samples which provides a step towards explaining the practical efficacy of transfer learning. Our results have depended upon a new general notion of task diversity--applicable to models with general tasks, features, and losses--as well as a novel chain rule for Gaussian complexities.
We hope to study the utility of representation learning and transfer learning in settings with dynamic feedback--i.e. The setting of reinforcement learning and bandits. Here we must address the additional challenge of balancing the need to learn shared structure (meta-exploration) with the need to exploit the estimated shared structure to achieve good performance (meta-exploitation).