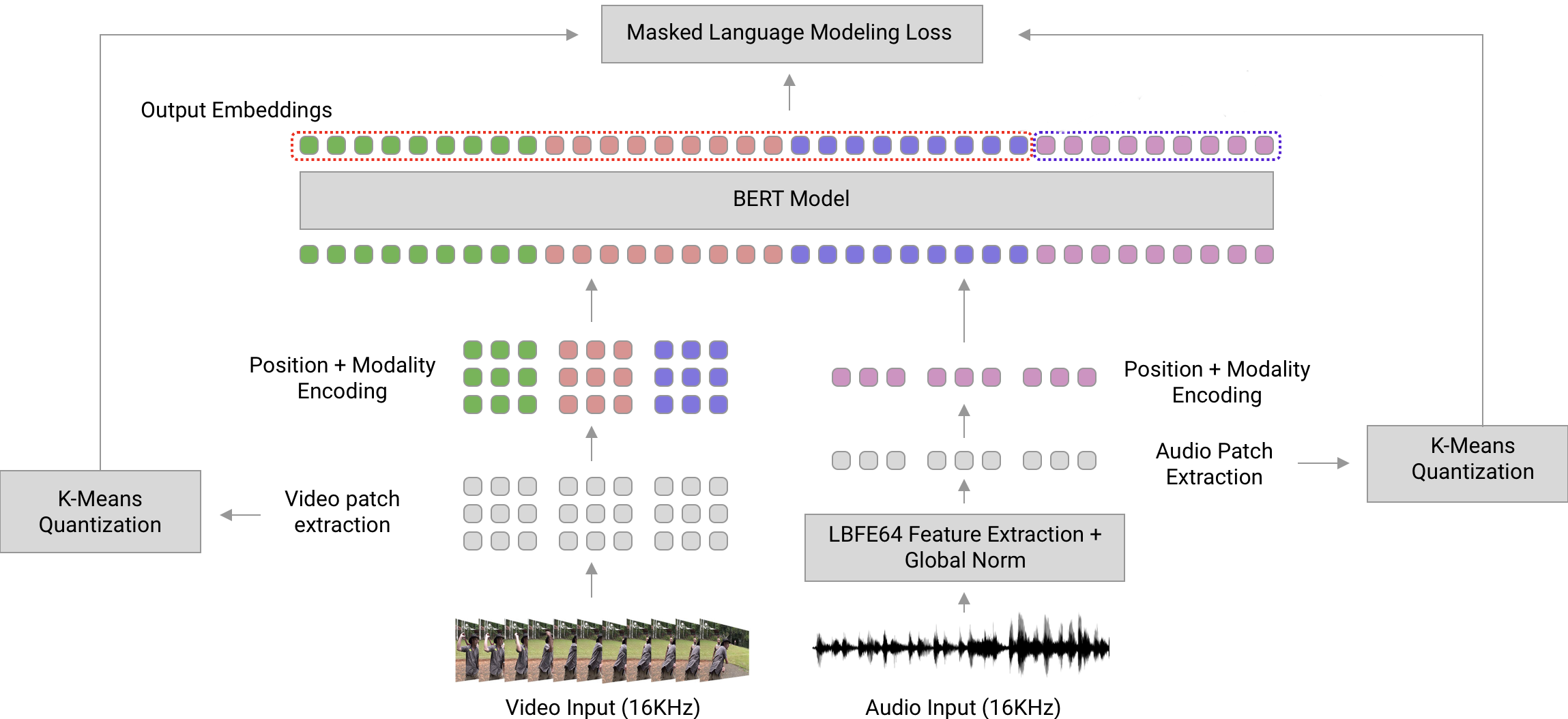
Learning strong representation of video data is a challenging task involving not only visual, but auditory, linguistic, and temporal data. Learning such representations becomes even more challenging with the added data volume and processing requirements over traditional image-only representation learning. In order to maintain user privacy, and empower highly...
