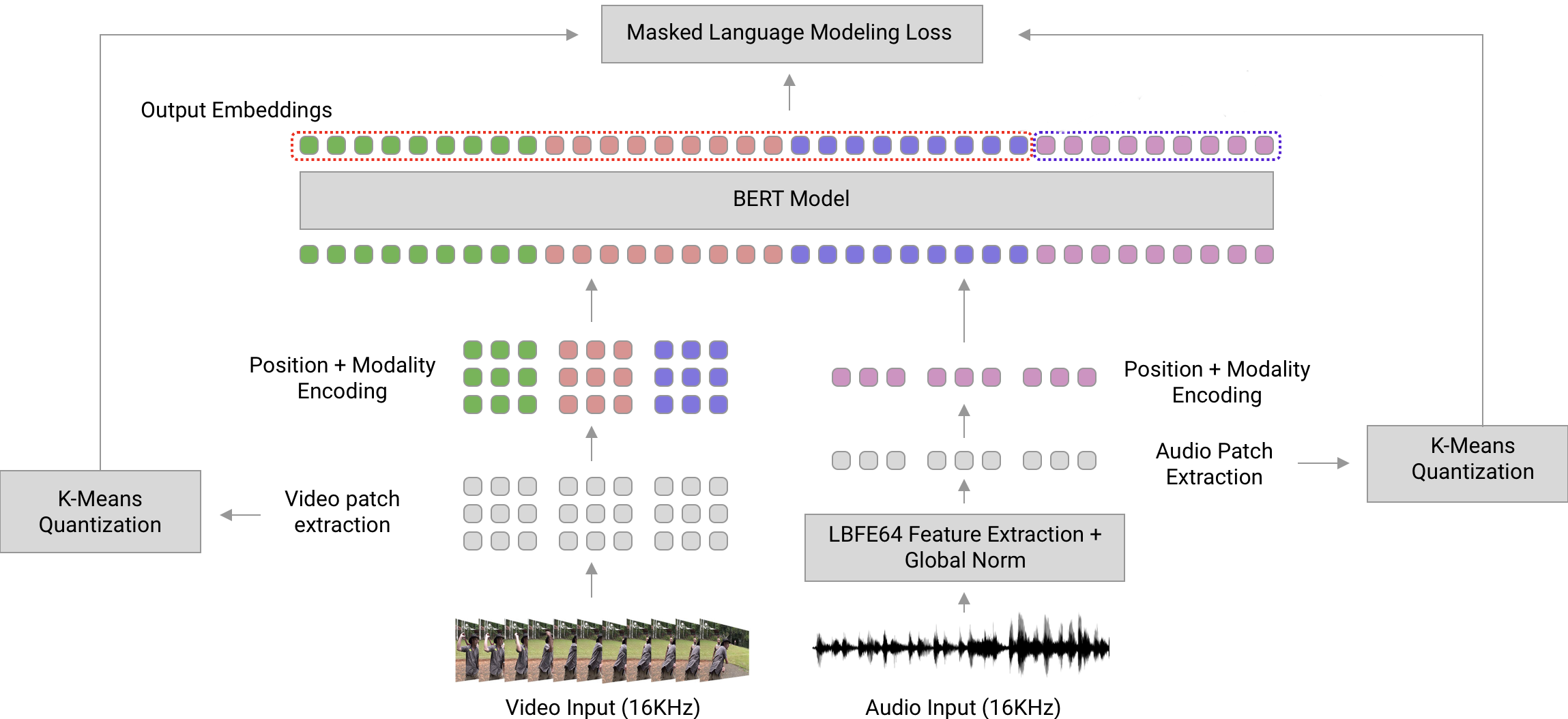
Learning strong representation of video data is a challenging task involving not only visual, but auditory, linguistic, and temporal data. Learning such representations becomes even more challenging with the added data volume and processing requirements over traditional image-only representation learning. In order to maintain user privacy, and empower highly customized end-user experiences, it is often desirable to perform on-device learning with very few samples, usually using low-power end-user devices. Unfortunately, with just one minute of video requiring up to 2000 times the processing power of an image, it may be impossible to deploy video-centric learning on an end-user device without strong pre-learned representations that can reduce the complexity of the learning task. Furthermore, such strong multimodal representations allow us to perform learning tasks with a fraction of the data, enabling highly customizable end-user experiences with a fraction of the required computational resources of traditional supervised learning.
Researchers
- David Chan, University of California, Berkeley
- John Canny, University of California, Berkeley
- Trevor Darrell, University of California, Berkeley
- Shalini Ghosh, Amazon
Overview
The goal of this proposal is to build state-of-the-art multimodal (audio, video, and text) models for video representation learning, based on state-of-the-art unsupervised and semi-supervised learning techniques. By learning such representations, we can improve the data and sample efficiency of video learning algorithms for on-device learning of myriad tasks including action recognition (inferring the key activity in a video sequence), video description (describing videos in natural language), video question-answering (answering questions about events in a video) and temporal action localization (determining where in a video actions occur) among others.
Our second goal is to explore compositional approaches leveraging out of domain data. Currently, many models struggle to handle open-domain data, since the training datasets are relatively small, and cannot be labeled at the scale of current vision datasets. One way we can overcome this limitation is by leveraging large external corpera from the vision and NLP communities. By building representations in shared multimodal latent spaces, we can leverage data that may otherwise be inaccessible by aligning several domains, and learning translation rules between them through model distillation, transfer learning, and domain adaptation.
Our third goal is to improve weak/unsupervised learning algorithms for multimodal video analysis. Unsupervised representation learning techniques such as SimCLRv2, MoCO, and BYOL can be unsatisfactory for video learning, due to their inherent lack of support for multi-modal data, and reliance on expensive multi-view transformations. We intend to pursue multimodal extensions to such frameworks by improving the data efficiency through in-latent space view-transformations, and multimodal compatibility of the supervised learning heads of such modern unsupervised frameworks to extract a learned data structure.
Links
- Contact: davidchan at berkeley.edu
Acknowledgements
Amazon has generously provided AWS credits to support this experiment.